 4006-967-446
4006-967-446 沃通数字证书商店
沃通数字证书商店云WAF如何防止敏感信息泄漏
发布日期:2021-08-03防敏感信息泄漏是Web应用防火墙针对网安法明确提出,企业运营者应当采取技术措施和其他必要措施,确保个人信息安全防止信息泄露、毁损、丢失。
在发生或者可能发生个人信息泄露、毁损、丢失的情况时,应当立即采取补救措施按照规定及时告知用户并向有关主管部门报告”所给出的安全防护方案。
防敏感信息泄漏功能针对网站中存在的敏感信息(尤其是手机号、***、***等信息)泄漏、敏感词汇泄露提供脱敏和告警措施,并支持拦截指定的HTTP状态码。
事实上做好水平权限控制也是防敏感信息泄漏重要的一环,数据的访问权限 数据脱敏等。防敏感信息泄漏属于DLP数据防泄漏范畴,本文只讨论云waf如何防敏感信息泄漏,DLP范围比较广,后面单独介绍。
网站中常见的造成信息泄漏的场景包括:
URL未授权访问(例如,网站管理后台未授权访问)。
越权查看漏洞(例如,水平越权查看漏洞和垂直越权查看漏洞)。
网页中的敏感信息被恶意爬虫爬取。
针对网站中常见的敏感信息泄露场景,防敏感信息泄漏提供以下功能:
针对网站页面中出现的个人隐私敏感数据进行检测识别,并提供预警和屏蔽敏感信息等防护措施,避免网站经营数据泄露。这些敏感隐私数据包括但不限于***号、手机号、***号等。
针对有可能暴露网站所使用的Web应用软件、操作系统类型,版本信息等服务器敏感信息,支持一键拦截,避免服务器敏感信息泄露。
根据内置的非法敏感关键词库,针对在网站页面中出现的相关非法敏感词,提供告警和非法关键词屏蔽等防护措施。
工作原理
防敏感信息泄露通过检测响应页面中是否带有***号、手机号、***号等敏感信息,发现敏感信息匹配命中后,根据所设置的匹配动作进行告警或者过滤敏感信息。其中,敏感信息过滤动作以*号替换敏感信息部分,从而达到保护敏感信息的效果。
防敏感信息泄露功能支持的Content-Type包括text/*、 image/*application/*等,涵盖Web端、app端和API接口。
针对特定URL页面中的敏感信息过滤:针对特定URL页面中存在的电话号码和***等敏感信息,配置相应的规则对其进行过滤或告警。例如,您可以通过设置以下防护规则,过滤admin.php页面中的***号敏感信息。
我们当前nginx是作为反向代理来使用,在配置proxy_hide_header前,通过浏览器我们可以看到主机响应头中包含php版本信息(X-Powered-By: PHP/5.4.43),我们的目的就是将这个显示内容从响应头中去掉。
请求头:
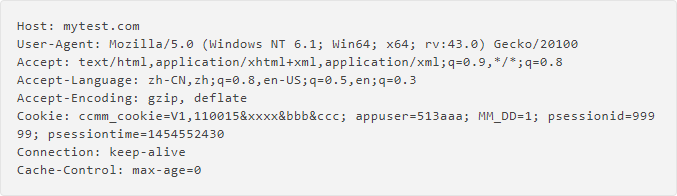
响应头:
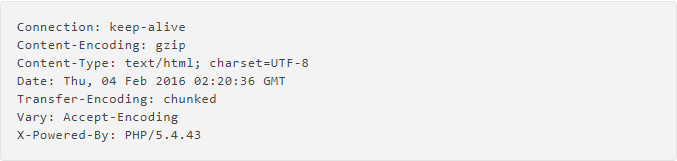
根据官网说明,proxy_hide_header 可在http, server, location区段使用。
语法:proxy_hide_header field;
默认值: —
上下文: http, server, location
nginx默认不会将“Date”、“Server”、“X-Pad”,和“X-Accel-…”响应头发送给客户端。proxy_hide_header指令则可以设置额外的响应头,这些响应头也不会发送给客户端。相反的,如果希望允许传递某些响应头给客户端,可以使用proxy_pass_header指令。
一般nginx反向代理会配置很多站点,每个站点配置费时费力而且少有遗漏主机信息还是会被泄露的。根据上面的说明,我们将proxy_hide_header 配置在http区段,如下所示:
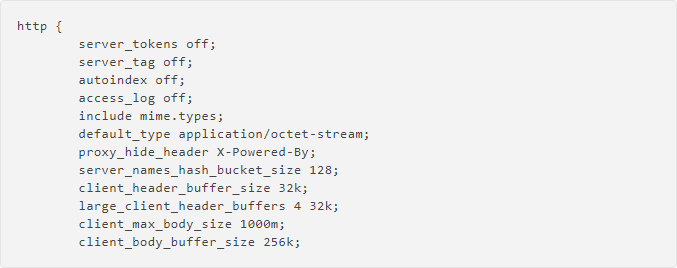
检查nginx配置文件语法:

重启nginx服务:

配置后的主机响应头信息:
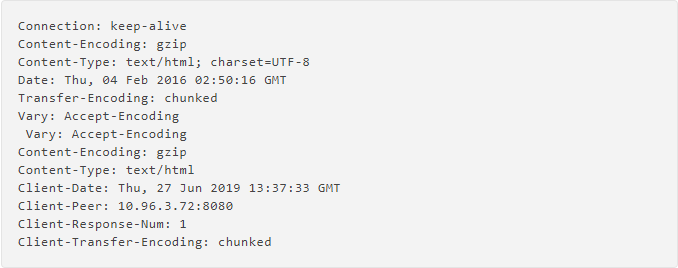
使源站返回不压缩response:
在请求时加一个过滤,去掉Accept-Encoding: gzip, deflate请求头,这样源站返回的始终是不压缩的response内容。
waf过滤敏感信息
Nginx实现资源压缩的原理是通过ngx_http_gzip_module模块拦截请求,并对需要做gzip的类型做gzip,ngx_http_gzip_module是Nginx默认集成的, 不需要重新编译,直接开启即可 。
nginx gzip 默认http1.1生效,因为nginx到upsteam回源的请求是http1.0协议,所以gzip version要配置成http1.0
这样在nginx回源的时候,如果rs返回的响应body是压缩的,那么在nginx需要对这个压缩过的body解压,然后过滤body内容,过滤后的内容重新赋给ngx.arg[1]
实现过滤效果。
踩过的坑:
1. 配置gzip version 为http1.1,rs返回的body始终为原body(未压缩),body_filter阶段得到的始终是原文。
2. rs返回的原body过滤后,在压缩返回client压缩格式的内容,client浏览器显示的始终未压缩body。
3. collections 判断content-lengt type处直接返回。需要修改。
正常思路:
nginx 从upstrean获取到压缩过or未压缩的body(未压缩暂时没完整测试),判断rs返回的body如果是压缩过的,那么进行解压。
解压后得到原文过滤,然后把过滤后的原文压缩返回给client。即:得到压缩->解压->过滤->压缩->返回。
如果从upstream得到的rsp body为原文,然后过滤→压缩→返回,浏览器显示的始终是压缩格式。为什么这样?总之不可以这样操作。
优化:
在body filter阶段,从rs得到压缩的body,解压赋给ngx.arg[1],然后解压后的原文过滤crs规则,命中规则后,在body_filter文件又得到rs body,然后解压或不解压
然后把命中规则的字段替换掉,敏感信息、手机号等。
rs返回的rsp body为未压缩格式,过滤body然后返回压缩格式的body,待测试。
mime类型判断,动静态文件 压缩解压效果。
未超过gzip min length条件下效果。
语法: gzip_min_length length
默认值: gzip_min_length 0
作用域: http, server, location
设置允许压缩的页面最小字节数,页面字节数从header头中的Content-Length中进行获取。
默认值是0,不管页面多大都压缩。
建议设置成大于1k的字节数,小于1k可能会越压越大。即: gzip_min_length 1024
gzip_min_length
当返回内容大于此值时才会使用gzip进行压缩,以K为单位,当值为0时,所有页面都进行压缩。
响应时间,主要看压缩解压缩是否占用过多请求时间
压缩效果,原来的5k压缩到1.2k
从这我们可以得出结论:
随着压缩级别的升高,压缩比有所提高,但到了级别6后,很难再提高;
随着压缩级别的升高,处理时间明显变慢;
gzip很消耗cpu的性能,高并发情况下cpu达到100%;
因此,建议:
不是压缩级别越高越好,其实gzip_comp_level 1的压缩能力已经够用了,后面级别越高,压缩的比例其实增长不大,反而很吃处理性能。
压缩一定要和静态资源缓存相结合,缓存压缩后的版本,否则每次都压缩高负载下服务器肯定吃不住。
gzip_disable
通过表达式,表明哪些UA头不使用gzip压缩
gzip_proxied
Nginx做为反向代理的时候启用:

如果源站配置成http1.1 才返回压缩的body,那么waf受到的响应为未压缩的格式。
如果此时的http请求为Accept-Encoding:gzip, deflate,那么waf在向client回应body时,会有Content-Encoding: gzip响应head。
waf处理逻辑得到响应head Content-Encoding: gzip,然后把rs返回的body压缩返回给client。
增加处理逻辑,在判断rs返回body为未压缩格式,http请求有请求为Accept-Encoding:gzip, deflate,即使有Content-Encoding: gzip响应head,也不压缩body。
进一步:如果rs返回未压缩waf也压缩bodyclient浏览器显示压缩过的乱码。

